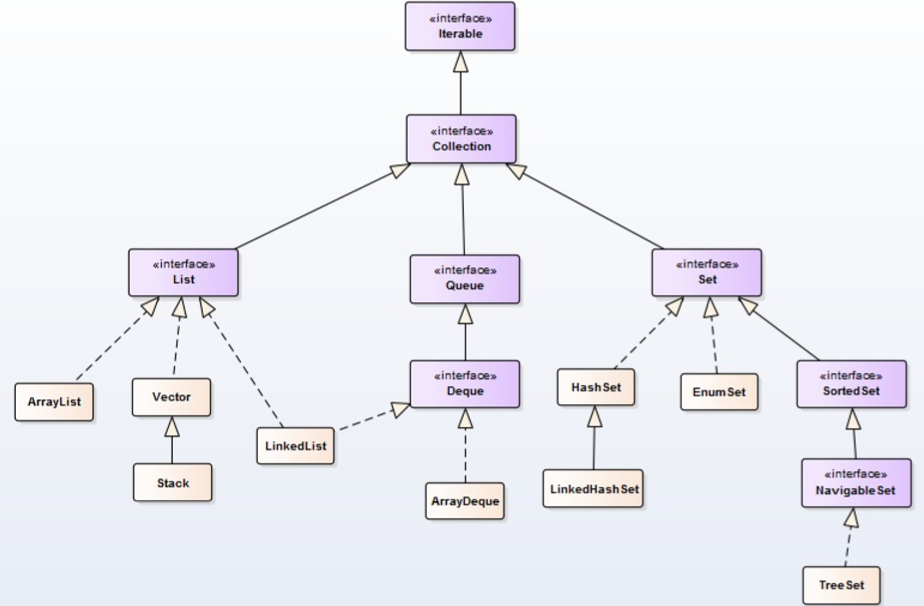
Collection
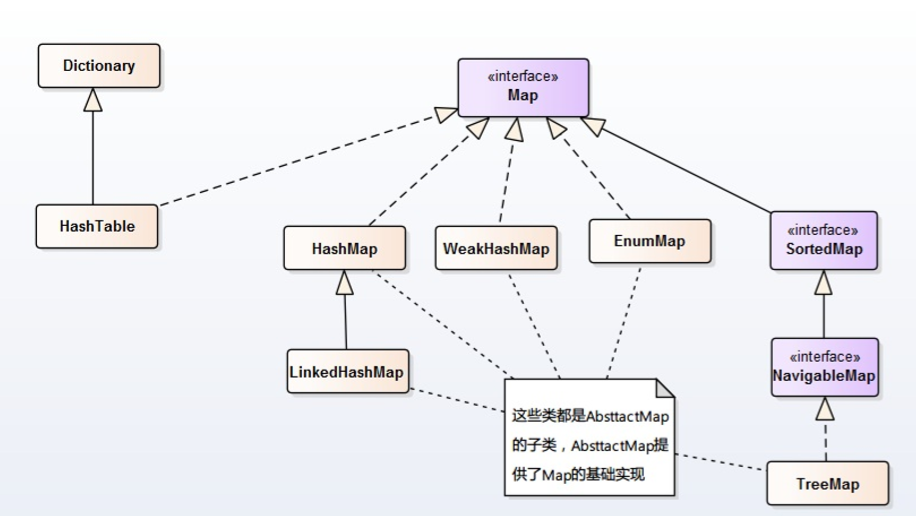
Map
工具类
Comparable 在 java.lang 包下,是一个接口,内部只有一个方法 compareTo():
public interface Comparable<T> {
public int compareTo(T o);
}
Comparable 可以让实现它的类的对象进行比较,具体的比较规则是按照 compareTo 方法中的规则进行。这种顺序称为 自然顺序。
compareTo 方法的返回值有三种情况:
e1.compareTo(e2) > 0 即 e1 > e2
e1.compareTo(e2) = 0 即 e1 = e2
e1.compareTo(e2) < 0 即 e1 < e2
注意:
1.由于 null 不是一个类,也不是一个对象,因此在重写 compareTo 方法时应该注意 e.compareTo(null) 的情况,即使 e.equals(null) 返回 false,compareTo 方法也应该主动抛出一个空指针异常 NullPointerException。
2.Comparable 实现类重写 compareTo 方法时一般要求 e1.compareTo(e2) == 0 的结果要和 e1.equals(e2) 一致。这样将来使用 SortedSet 等根据类的自然排序进行排序的集合容器时可以保证保存的数据的顺序和想象中一致。
Comparator 定制排序
Comparator 在 java.util 包下,也是一个接口,JDK 1.8 以前只有两个方法:
public interface Comparator<T> {
public int compare(T lhs, T rhs);
public boolean equals(Object object);
}
JDK 1.8 以后又新增了很多方法:基本上都是跟 Function 相关的,这里暂不介绍 1.8 新增的。
从上面内容可知使用自然排序需要类实现 Comparable,并且在内部重写 comparaTo 方法。
而 Comparator 则是在外部制定排序规则,然后作为排序策略参数传递给某些类,比如 Collections.sort(), Arrays.sort(), 或者一些内部有序的集合(比如 SortedSet,SortedMap 等)。
使用方式主要分三步:
1、创建一个 Comparator 接口的实现类,并赋值给一个对象 ,在 compare 方法中针对自定义类写排序规则。
2、将 Comparator 对象作为参数传递给 排序类的某个方法
3、向排序类中添加 compare 方法中使用的自定义类
其实可以看到,Comparator 的使用是一种策略模式。
排序类中持有一个 Comparator 接口的引用:
Comparator<? super K> comparator;
而我们可以传入各种自定义排序规则的 Comparator 实现类,对同样的类制定不同的排序策略。
总结
Java 中的两种排序方式:
1、Comparable 自然排序。(实体类实现)
2、Comparator 是定制排序。(无法修改实体类时,直接在调用方创建)
Comparable是排序接口;若一个类实现了Comparable接口,就意味着“该类支持排序”。而Comparator是比较器;我们若需要控制某个类的次序,可以建立一个“该类的比较器”来进行排序。
我们不难发现:Comparable相当于“内部比较器”,而Comparator相当于“外部比较器”。
同时存在时采用 Comparator(定制排序)的规则进行比较。
对于一些普通的数据类型(比如 String, Integer, Double…),它们默认实现了Comparable 接口,实现了 compareTo 方法,我们可以直接使用。
而对于一些自定义类,它们可能在不同情况下需要实现不同的比较策略,我们可以新创建 Comparator 接口,然后使用特定的 Comparator 实现进行比较。
Object类是类继承结构的基础,所以是每一个类的父类。所有的对象,包括数组,都实现了在Object类中定义的方法。null的引用值x,x.equals(x)一定是true。null的引用值x和y,当且仅当x.equals(y)是true时,y.equals(x)也是true。null的引用值x、y和z,如果x.equals(y)是true,同时y.equals(z)是true,那么x.equals(z)一定是true。null的引用值x和y,如果用于equals比较的对象信息没有被修改的话,多次调用时x.equals(y)要么一致地返回true要么一致地返回false。null的引用值x,x.equals(null)返回false。虽然,每个Java类都包含hashCode() 函数。但是,仅仅当创建并某个“类的散列表”(关于“散列表”见下面说明)时,该类的hashCode() 才有用(作用是:确定该类的每一个对象在散列表中的位置;其它情况下(例如,创建类的单个对象,或者创建类的对象数组等等),类的hashCode() 没有作用。
上面的散列表,指的是:Java集合中本质是散列表的类,如HashMap,Hashtable,HashSet。
也就是说:hashCode() 在散列表中才有用,在其它情况下没用。在散列表中hashCode() 的作用是获取对象的散列码,进而确定该对象在散列表中的位置。
这里所说的“不会创建类对应的散列表”是说:我们不会在HashSet, Hashtable, HashMap等等这些本质是散列表的数据结构中,用到该类。例如,不会创建该类的HashSet集合。
在这种情况下,该类的“hashCode() 和 equals() ”没有半毛钱关系的!
这种情况下,equals() 用来比较该类的两个对象是否相等。而hashCode() 则根本没有任何作用,所以,不用理会hashCode()。
2. 第二种 会创建“类对应的散列表”
这里所说的“会创建类对应的散列表”是说:我们会在HashSet, Hashtable, HashMap等等这些本质是散列表的数据结构中,用到该类。例如,会创建该类的HashSet集合。
在这种情况下,该类的“hashCode() 和 equals() ”是有关系的:
1)、如果两个对象相等,那么它们的hashCode()值一定相同。这里的相等是指,通过equals()比较两个对象时返回true。
2)、如果两个对象hashCode()相等,它们并不一定相等。
因为在散列表中,hashCode()相等,即两个键值对的哈希值相等。然而哈希值相等,并不一定能得出键值对相等。补充说一句:“两个不同的键值对,哈希值相等”,这就是哈希冲突。
此外,在这种情况下。若要判断两个对象是否相等,除了要覆盖equals()之外,也要覆盖hashCode()函数。否则,equals()无效。
例如,创建Person类的HashSet集合,必须同时覆盖Person类的equals() 和 hashCode()方法。
如果单单只是覆盖equals()方法。我们会发现,equals()方法没有达到我们想要的效果。
1、经典方式
public class User {
private String name;
private int age;
private String passport;
//getters and setters, constructor
@Override
public boolean equals(Object o) {
if (o == this) return true;
if (!(o instanceof User)) {
return false;
}
User user = (User) o;
return user.name.equals(name) &&
user.age == age &&
user.passport.equals(passport);
}
//Idea from effective Java : Item 9
@Override
public int hashCode() {
int result = 17;
result = 31 * result + name.hashCode();
result = 31 * result + age;
result = 31 * result + passport.hashCode();
return result;
}
}
注意:不同类型hashCode值的计算可以采用如下公式。
| Field类型 | 计算公式 |
| boolean | hashCode=(f?0:1); |
| 整数类型(byte,short,char,int) | hashCode=(int)f; |
| long | hashCode=(int)(f^(f>>>32)); |
| float | hashCode=Float.floatToIntBits(f); |
| double | long l=Double.doubleToLongBits(f);
hashCode=(int)(l^(l>>>32); |
| 普通引用类型 | hashCode=f.hashCode(); |
使用系数为31的原因如下:
- 31是一个素数,素数作用就是如果我用一个数字来乘以这个素数,那么最终的出来的结果只能被素数本身和被乘数还有1来整除!。(减少冲突)
- 31可以 由i*31== (i<<5)-1来表示,现在很多虚拟机里面都有做相关优化.(提高算法效率)
- 选择系数的时候要选择尽量大的系数。因为如果计算出来的hash地址越大,所谓的“冲突”就越少,查找起来效率也会提高。(减少冲突)
- 并且31只占用5bits,相乘造成数据溢出的概率较小。
2、JDK 7
import java.util.Objects;
public class User {
private String name;
private int age;
private String passport;
//getters and setters, constructor
@Override
public boolean equals(Object o) {
if (o == this) return true;
if (!(o instanceof User)) {
return false;
}
User user = (User) o;
return age == user.age &&
Objects.equals(name, user.name) &&
Objects.equals(passport, user.passport);
}
@Override
public int hashCode() {
return Objects.hash(name, age, passport);
}
}
3、Apache Commons Lang
import org.apache.commons.lang3.builder;
public class User {
private String name;
private int age;
private String passport;
//getters and setters, constructor
@Override
public boolean equals(Object o) {
if (o == this) return true;
if (!(o instanceof User)) {
return false;
}
User user = (User) o;
return new EqualsBuilder()
.append(age, user.age)
.append(name, user.name)
.append(passport, user.passport)
.isEquals();
}
@Override
public int hashCode() {
return new HashCodeBuilder(17, 37)
.append(name)
.append(age)
.append(passport)
.toHashCode();
}
}


文章评论